Part I – The Model Landscape: The Frontier of Reasoning
By Bhanu Nallagonda, Cofounder, Ogha Technologies March ‘26
The relentless march of model performance continued in 2026, but the metric of success shifted irrevocably. In previous years, the vibe of a model was its fluency, creativity and the ability to hold a conversation was the primary differentiator. In 2025, the industry pivoted hard toward reasoning and utility. The landscape changed from “Can it write a poem?” to “Can it debug this repository, plan a logistics route and execute the API calls without hallucinating?”
The Titans: A Comparative Analysis
The release cycle of the AI Titans was dominated by the intensification of the rivalry between the primary research labs—Google DeepMind, OpenAI and Anthropic—along with the surging capabilities of open-weight contenders that have fundamentally altered the competitive landscape.
Google: The Gemini 3 Era
In 2025, Google successfully shed the perception of being a “fast follower” and reasserted its research dominance with the release of the Gemini 3 family. Unlike its predecessors, which were defined primarily by their native multimodal architecture, Gemini 3 was defined by “big leaps in reasoning” and efficiency.
The Gemini 3 Pro model demonstrated that improvements in agentic capability could be decoupled from massive parameter scaling. Instead, Google focused on architectural refinements that allowed for better decision-making in multi-step workflows. This “reasoning-first” approach allowed Gemini 3 to excel in scientific domains, boosting breakthroughs in genomics (in gene editing, disease interpretation and drug discovery etc.) and quantum computing (helping develop expert level empirical software). Furthermore, the introduction of Gemma 3 continued Google’s aggressive push into the open-model space, offering developers powerful local inference capabilities that rivalled the previous year’s frontier models, effectively commoditizing “GPT-4 class” intelligence for local devices.
OpenAI: The Bifurcation of Intelligence
OpenAI’s strategy in 2025 diverged into two distinct lineages, acknowledging that “creative fluency” and “logical reasoning” might require different architectures, while continuing its consumer focus.
- If GPT-5.2 was the apex of fluid conversation, GPT-5.4 is the ‘current’ undisputed master of autonomous execution. It is the first flagship to successfully unify the ‘thinking’ depth of a reasoning model with the ‘doing’ agility of a specialized agent. By scoring a record 83% on the GDPval benchmark across 44 professional occupations, it has effectively moved beyond being a ‘super-spellcheck’ to becoming a digital specialist in law, finance, and engineering. While there were some rumours of 2M token context window, it debuted with a 1M long context window, effectively eliminating the need for complex RAG (Retrieval) workarounds in 90% of use cases. GPT-5.4 doesn’t just write code; it operates the computer. It can navigate a desktop environment, use a mouse and keyboard to interact with non-API legacy software, and perform multi-step workflows across different applications with a 75% success rate on OSWorld-Verified—surpassing the measured human baseline. It can extend the lifetime of these legacy software, while competing for the ‘seat’ of a Junior Investment Analyst or a Staff Engineer. Just to elaborate, Google’s Gemini’s score was based on earlier terminal based benchmarks and humans score 72.4 on this (for whatever be the reasons) and Claude 4.6 Sonnet at 72.5, a shade above the humans!
- The o-Series (o1, o3, o3-mini): The real paradigm shift, however, was operationalized by the o-series. These models introduced the concept of “test-time compute” or “thinking” phases. When asked a complex math or coding problem, o3 does not simply predict the next token. It generates hidden chains of thought, exploring multiple logical paths, verifying its own assumptions and backtracking if it detects an error, before finally outputting a response. This “System 2” thinking significantly reduced hallucination rates in high-stakes tasks.
Anthropic: The Enterprise Workhorse
Anthropic continued to cultivate its reputation for safety and reliability, a positioning that paid dividends in the enterprise market. The Claude 4.5 series, particularly Claude Opus 4.5, emerged as the heavy lifter for complex engineering tasks.
- Beyond Coding Dominance: While Claude Opus 4.5 conquered the ‘contamination-free’ benchmarks, Claude Opus 4.6 Thinking has redefined the ‘contamination-free’ organization. It is no longer just solving GitHub issues; it is managing them. By introducing Adaptive Thinking—a native reasoning layer that self-scales its ‘effort’—and a massive 1 million token context window, Opus 4.6 has become the gold standard for full-repository refactoring. It is the first model to score a staggering 80.8% on SWE-bench Verified, effectively ending the era of ‘file-by-file’ coding in favor of ‘system-wide’ orchestration.
- Contextual Mastery: Its massive context window and superior instruction-following capabilities made it the preferred engine for many enterprise agentic frameworks.
So it is becoming rather obvious that different leaders are pursuing different objectives, which is a good thing and that also makes not directly comparable, perhaps more so in future if they diverge more in their paths, leaving the user to choose what is best suited for their task on hand.
The Open-Weight Insurgency
Perhaps the most disruptive trend of 2025 was the compression of the performance gap between proprietary (closed) and open-weight models. Stanford’s AI Index Report 2025 highlighted that the performance difference on some benchmarks shrank from a significant 8% to a negligible 1.7% within a single year.

There are allegations that models gaming the benchmarks with distillation, so while their benchmark performance is excellent, the real world performance is not at the same level (Vibe Divergence). There is some truth in this and most of the models use synthetic data generated by frontier models for finetuning through distillation.
Models like Llama 3.3, DeepSeek-V3 and Qwen 3 provided enterprise-grade performance at a fraction of the cost. DeepSeek-V3, in particular, stunned the industry by offering performance parity with GPT-4 in coding tasks while being available as free download, forcing closed providers to compete on service, reliability and extreme-frontier capabilities rather than raw intelligence alone.
The Crisis of Measurement: Benchmarking
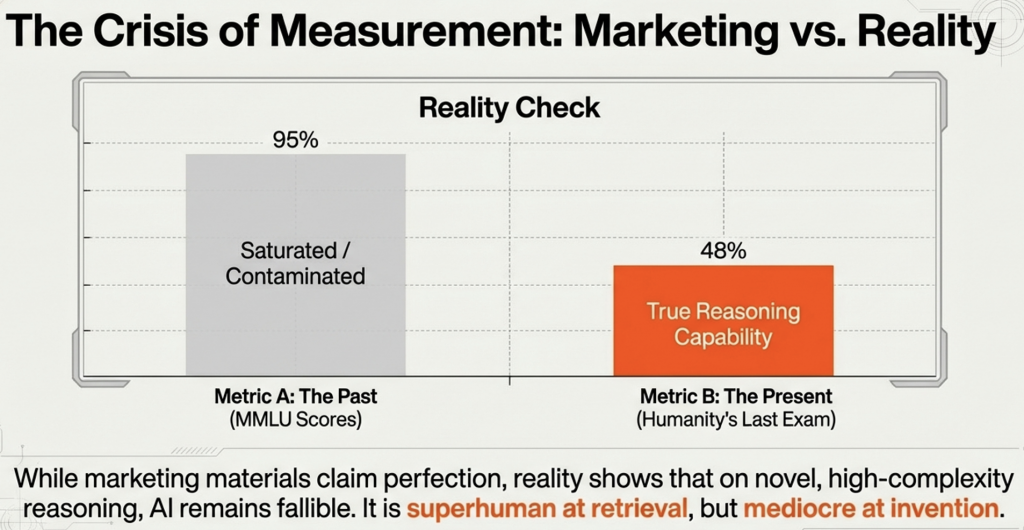
As models saturated traditional benchmarks like MMLU (Massive Multitask Language Understanding) with scores nearing 90%+, the industry faced a crisis of measurement. “Contamination”—the phenomenon where models memorize test questions present in their training data—rendered many classic benchmarks useless. In response, 2025 saw the rise of “living” benchmarks designed to be un-gameable.
LiveBench and Humanity’s Last Exam
The inadequacy of static benchmarks led to the adoption of LiveBench and “Humanity’s Last Exam” as the new gold standards for frontier evaluation.
- Methodology: Sponsored by Abacus.AI, LiveBench introduced a regime of regularly released, new questions with objective ground-truth answers. This design specifically limits potential contamination, as the questions did not exist when the models were trained.
- The Reality Check: On these rigorous tests, the gap between the absolute frontier and the “efficient” tier became starkly visible. While marketing materials claimed near-perfect scores, reality showed that on the hardest tasks, even the best models struggled. Gemini 3 Pro and Kimi K2 Thinking led the pack on Humanity’s Last Exam, but with scores only in the 45-50% range. This sobering data revealed that while AI is superhuman at retrieval, it remains fallible at novel, high-complexity reasoning.
SWE-Bench: The Coding Crucible
For software engineering tasks, SWE-Bench Pro became the definitive arena. Unlike simple coding contests (like HumanEval), SWE-Bench evaluates a model’s ability to navigate a complex, multi-file repository and fix a specific issue—a task representative of a real software engineer’s daily work.The New Ceiling: By late 2025, Claude Opus 4.5 and Gemini 3 Pro were trading the top spot, achieving resolution rates around 43-46%. While this represents a massive leap from the single-digit success rates seen in 2023, it also highlights that more than half of complex software engineering tasks still require human intervention.
The Frontier Model Leaderboard
| Rank | Model | Provider | Benchmark/Signal Highlight |
| 1 | GPT-5.4 Thinking | OpenAI | 75% on OSWorld-Verified; First model to exceed human baseline in native computer-use. |
| 2 | Claude Opus 4.6 (Thinking) | Anthropic | 80.8% on SWE-bench Verified; Leader in multi-agent orchestration and architectural refactoring. |
| 3 | Gemini 3.1 Pro (Preview) | 77.1% on ARC-AGI-2; Highest verified score in novel logic and pattern inference. | |
| 4 | Grok 4.1 Thinking | xAI | 1483 Arena Elo; Holds #1 in human preference for creative and “unconstrained” reasoning. |
| 5 | Kimi K2.5 Thinking | Moonshot AI | #1 for Agent Swarm; Can orchestrate up to 100 concurrent sub-agents for massive parallel tasks. |
| 6 | Seed 2.0 Pro | ByteDance | 89.5 on VideoMME; Dominates in professional video understanding and temporal reasoning. |
The key aspect of the leader board is that the leadership keeps changing with each of the leading players releasing their latest and greatest model and shuffling the deck. I confess that I needed to revise this table as I write this in March 2026.
Another aspect is that the time a model spends at the top of the leadership board is also shrinking as the competition intensifies and more capable models are released regularly and more frequently and there does not seem to be a finish line for this race anytime soon. Needless to say, the contents of above table could change between the time I write this and you read it.
However, there are no new players breaking into the ranks of top 3 and it could become increasingly difficult to do so, but let us not rule out any breakthroughs so soon.
As of early 2026, Hugging Face hosts over 2.1M models. The community reached the 1M model milestone in mid 2024. So the growth rate or the ferocity of the number of models can be estimated.
The number of truly frontier class models would be about 50 as of the writing.
While there are a much smaller number of notable and a few original foundational models, there are millions of variants. Then there are unknown number of private models and internal fine tunes.
Comparison of Model Tiers (Feb 2026)
| Model Tier | Estimated Count | Key Examples |
| Frontier Models | < 50 | GPT-5.2, Claude 4.5, Gemini 3 |
| Notable Models | ~4,000 | DeepSeek-V3, Llama-4, Mistral-Next |
| Open-Source (Public) | 2.1 Million+ | Hugging Face Repositories |
| Private Enterprise | ~12–15 Million (estimated) | Proprietary internal tools |
Natural Language Processing Models dominate the landscape with about 58-60% of share. Computer Vision Models are the next with ~20%. Audio and Speech models about 15% and finally Multimodal and others forming the rest i.e. about 5-6%. The fastest growing models are the Agentic and Reasoning models followed by Vision Language Models (VLMs).
Company-Specific Roadmaps
| Company | Flagship Model (2026) | Strategic Focus & Current Pursuit |
| OpenAI | o3 / o4-mini / GPT-5 | The AI Super-Assistant: Moving toward a unified “Frontier” model that acts as a primary interface for all digital tasks. Investing heavily in custom silicon to lower inference costs. |
| Gemini 3 (Pro/Ultra) | The Personalized Ecosystem: Deep integration with Google Workspace and Chrome. “Auto Browse” features allow Gemini to book tickets and manage travel natively within the browser. | |
| Anthropic | Claude Opus 4.6 | Trust & Computer Use: Doubling down on “Computer Use” (Claude moving the mouse/clicking buttons) and legal/financial “High-Stakes Reasoning” where auditability is non-negotiable. |
| Meta | Llama 4 (Scout/Maverick) | The Open Infrastructure: Maintaining the open-source lead. Llama 4 uses a sparse MoE architecture with a 10M context window to enable self-hosting for massive enterprise RAG systems. |
OpenAI: From Monolith to Portfolio
OpenAI has abandoned the “one model for everyone” approach. Their 2026 roadmap features GPT-5.2 for premium knowledge work and gpt-oss (open-weight) models to defend against Meta. They are also testing “AI Inboxes” and “Search AI Mode” that checkout shopping carts directly via a Universal Commerce Protocol.
Google: “Agentic Vision” & Personal Intelligence
Google’s Gemini 3 Flash now features “Agentic Vision.” Unlike passive snapshots, the model “explores” an image or video to find tiny details, drastically reducing hallucinations in visual tasks. Their focus is on Personal Intelligence – connecting to your Photos, Gmail, and History to become a “partner who is already up to speed”.
Anthropic: “Computer Use” & Agentic Coding
Anthropic is the leader in Autonomous Software Engineering. Their report on “Agentic Coding” shows Claude-based agents refactoring 12.5 million lines of code in 7 hours with 99.9% accuracy. They are pursuing “Foundry” – a platform where agents operate with sovereign-level trust and governance.
Meta: Llama Models and massive context window
Llama 4 Scout model, released by Meta on April 5, 2025, officially supports a 10-million-token context window. This was a significant technical milestone, making it the first publicly available open-weight model to offer such a massive capacity – surpassing rivals like GPT-4o (128K) and Gemini 1.5 Pro (2M) at its launch.
The Llama 4 family consists of different models with varying context capabilities:
- Llama 4 Scout (109B total / 17B active): Features the full 10 million token window.
- Llama 4 Maverick (400B total / 17B active): Supports a 1 million token window.
- Llama 4 Behemoth (2T total / 288B active): Announced as a flagship “teacher” model capable of even more complex reasoning, though initially released in preview for research.
Pushing the Frontier in 2027
By 2027, the focus is expected to shift toward Mechanistic Interpretability (understanding why a model thinks) and Verifiable Rewards. This will allow AI to be used in high-risk zones like autonomous surgical assistants or grid-level energy management where “black box” logic is currently a legal blocker.
Mechanistic Interpretability is considered a core pillar of transparent and explainable AI (XAI).

Part II – The Economics of Intelligence: A Tale of Two Curves follows..
It’s really interesting to see how much focus is now on reasoning abilities – fluency alone doesn’t seem to cut it anymore.