By Dhanyasri A, Virtual Intern, (B.E. Comp. Sc., Final Year)
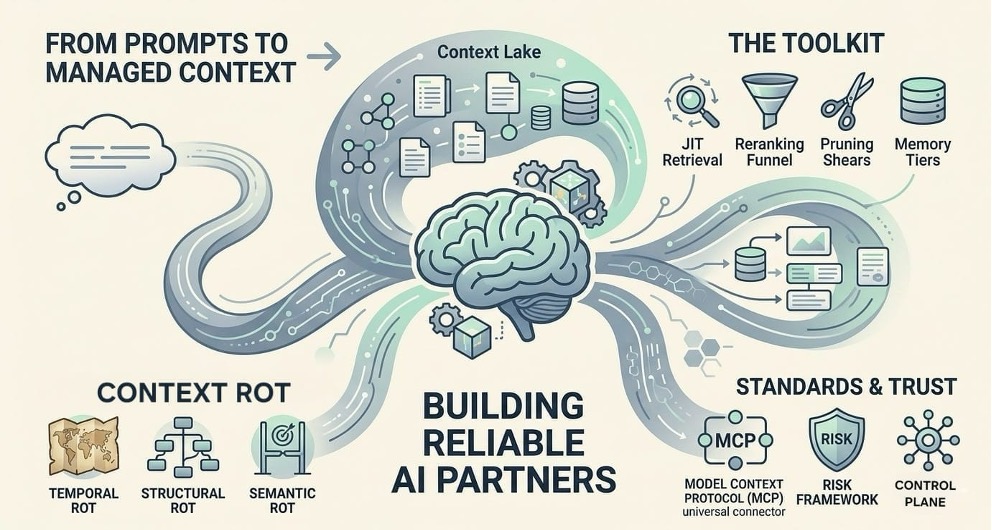
From Simple Prompts to Managed Context
The world of AI is moving away from just “prompt engineering”, the art of picking the right words, to a more serious discipline called Context Engineering. Think of prompt engineering as a bit of “word magic” that worked for early models but is not sufficient enough by itself for big businesses. Context engineering, on the other hand, is the professional way we design and organize the information an AI sees. It is about making sure the model actually knows the surrounding information of what you want and gives you useful results. To distinguish these better, it helps to think of Prompt Engineering as the ‘Command’ and Context Engineering as the appropriate and precise “Knowledge Base” for AI.
In professional AI development, we are seeing that Prompt Engineering has become a baseline skill, while Context Engineering is becoming the high-value discipline. This shift is happening because we have realized that an AI’s performance depends less on how many billions of parameters it has and more on the quality of the “context” it is given right when it needs to do a job. Leaders in the industry are now saying that giving AI the right context is the most important skill for building tools people can actually trust.
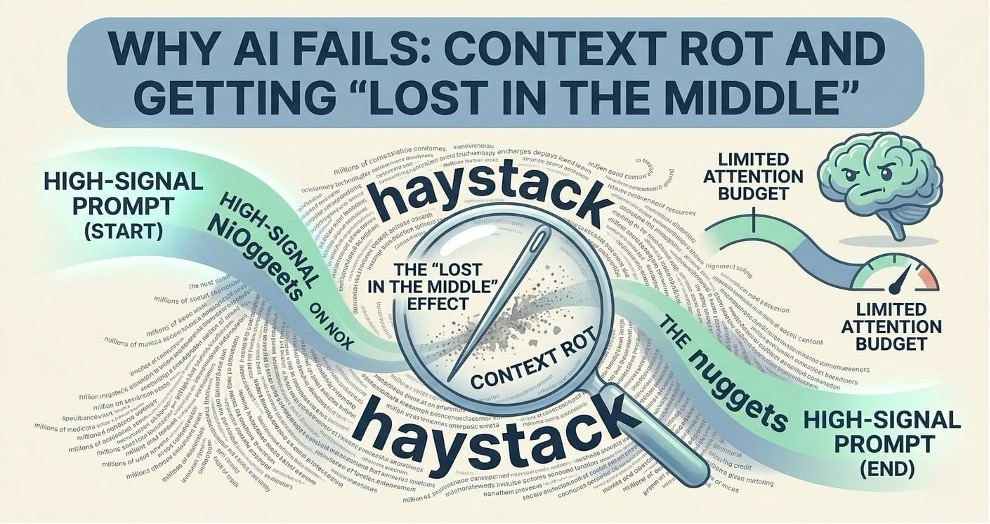
Why AI Fails: Context Rot and Getting “Lost in the Middle”
Even though modern AI can now “read” millions of words at once, a strange problem has popped up: the more info you give it, the worse it often performs. This is what we call Context Rot. It happens because of how AI models are built. They have a limited “attention budget”. When you flood them with too much data, that attention gets stretched thin.
The “Lost in the Middle” Problem
Research shows that if you put an important fact at the very beginning (primacy) or the very end (recency) of a long document, the AI usually finds it. But if that ‘needle’ of information is buried in the middle of a massive ‘haystack’ of text, the AI often misses it entirely. This is caused by a natural bias in how these models are trained. The U-Shaped performance curve remains a persistent hurdle for engineers. While the recent models have significantly improved their “Needle in a Haystack” scores, often hitting 99% on simple retrieval, they still struggle with Multi-Needle Reasoning.
Types of Contextual Decay
In a business setting, this “rot” usually shows up in three ways:
Temporal Rot: This is when the AI uses old, out-of-date info to make a decision today. It is like trying to navigate a city using a map from ten years ago.
Structural Rot: This happens when the relationships between things change. For example, like when a company reshuffles its departments, but the AI still thinks the old hierarchy is in place.
Semantic Rot: This is the most subtle version. The data itself has not changed, but what it means to the business has changed because the company’s goals have shifted.
The Cost of “Wheel-Spin”
Context rot isn’t just a technical glitch, it’s expensive. When an AI agent gets stuck looking at old or messy data, it enters a “wheel-spin” cycle. It keeps re-planning and retrying the same task over and over. This wastes money on computing costs and slows everything down without actually getting the job done.
The Context Engineering Toolkit: How We Fix It
To stop the AI from getting overwhelmed, engineers use a few different strategies to make sure only the most important “high-signal” info reaches the model.
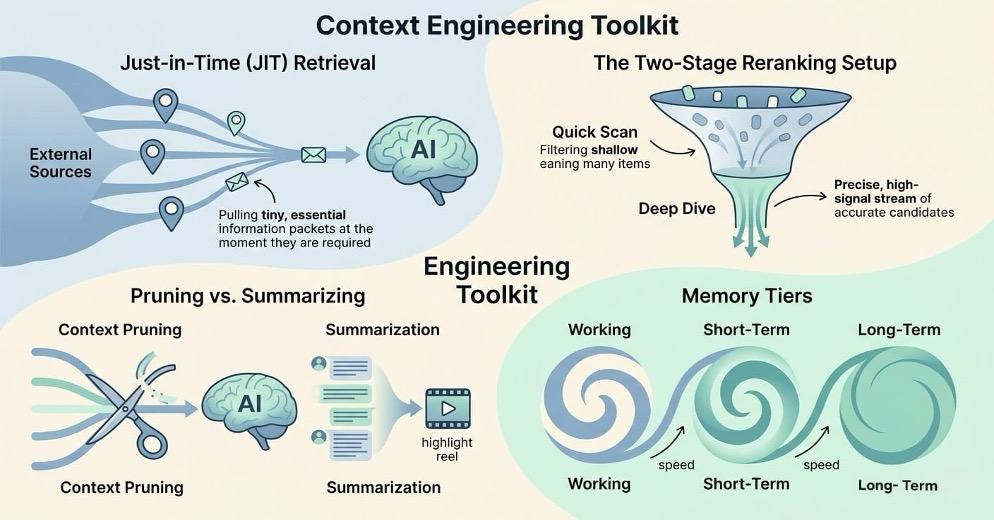
Just-in-Time (JIT) Retrieval Instead of dumping a huge dataset into the AI all at once, we can use JIT retrieval. This means the system holds onto small “pointers” to the data and only loads the specific parts it needs at the exact moment it needs to think through a problem.
The Two-Stage Reranking Setup Most basic search systems find things that are “similar” but not necessarily “right.” To fix this, we can use a two-step process:
The Quick Scan: A fast tool grabs the top 50 or 100 likely candidates.
The Deep Dive: A more powerful model re-checks those candidates to pick the best ones. This simple change can make the AI’s answers to be about 33-40% more accurate.
Pruning vs. Summarizing There are two main ways to stay under that “attention budget”:
Context Pruning: This is basically a filter. It cuts out any sentences or bits of data that don’t help answer the question before the AI even sees them.
Summarization: This shrinks down long conversations into a “highlight reel”. It helps the AI remember the “gist” of a long chat, though there’s a small risk of losing tiny details that might matter later.
Memory Tiers Modern AI systems manage memory a lot like a computer does. They have Working Memory for what’s happening right now, Short-Term Memory for the current session and Long-Term Memory for permanent records. This keeps the AI from getting “flooded” while still letting it remember important facts over time.
Setting the Standard: The Model Context Protocol (MCP)
By 2026, the Model Context Protocol (MCP) had established itself as the industry’s standard. Overseen by the Agentic AI Foundation, it functions as a sort of “universal language” for AI. This protocol enables various AI agents to interact with tools, APIs and databases, eliminating the need for configurations for each individual connection. It has become so popular that it’s now the standard way we deliver context to AI systems everywhere.
Keeping Things Safe: The Context Control Plane
As AI agents get more independent, the companies need a way to manage them. This is done through a Context Control Plane. Think of it as a control room that decides what data and permissions the AI is allowed to have.
The Three R’s of Management
To be reliable, a system needs to follow three rules:
Relevance: The info must be up-to-date and actually related to the task.
Reliability: We need to know exactly where the data came from.
Retention: AI needs to be able to build up “institutional knowledge” over time.
Using the NIST Framework
We also use the NIST AI Risk Management Framework to keep things on track. This involves:
Governing: Creating a culture where people are accountable for how the AI behaves.
Mapping: Figuring out where the AI might have biases or blind spots.
Measuring: Tracking how often the AI gets things right or makes things up.
Managing: Fixing problems like “data drift” before they cause issues.
Conclusion: Context Is the New Currency
Looking ahead to the end of 2026, the real difference between a successful AI project and a failure won’t be the size of the model. It will be the quality of the context. The companies that win will be the ones that treat context as a top priority, building “Context Lakes” and using tools like MCP to keep their AI smart. We’re moving from a world where we just “talk” to AI to a world where AI truly understands the complex setting it’s working in. It’s the final step in making AI a reliable partner instead of just a fancy chatbot.
Please also read my co-authored paper on “ML Assisted Diagnosis for Parkinson’s Disease” published by IEEE at:
Part IV: Vibe Coding and the Paradox of Democratization
By Bhanu Nallagonda, Cofounder, Ogha Technologies
April ‘26
One of the most culturally significant trends of 2025 was the mainstreaming of “Vibe Coding” and phenomenally accelerating in the 1st quarter of 2026. This phenomenon fundamentally altered the relationship between humans and software creation. Hitherto, what was not possible by the end of 2025 i.e. having a fully working code as an output in one go, is a reality just after 2 months by February of 2026.
Vibe Coding – Definition and its Evolution
Coined initially by AI researcher Andrej Karpathy, “vibe coding” refers to a development style where the human provides the intent (the “vibe”) via natural language and the AI handles the implementation details (syntax, boilerplate, libraries).
Tools like Cursor, Lovable, Bolt and Replit etc. became the standard environments for this workflow, with OpenAI and Claude Code again being the frontiers in providing the brains or the leading models. Initially, pure vibe coding is used for “throwaway” weekend projects and rapid prototyping. The standard vibe coding evolved into Architectural Vibe Coding, using AI agents to build and maintain complex, production-grade systems where the human’s primary role is system design and orchestration. Essentially it is a specification driven development with multi-agent orchestration – the architect agent, the coder agent and SRE (Site Reliability Engineer) agent and so on. An auditor agent or the AI reviewer, like CodeRabbit, Anthropic’s Claude Code Review or other agents are used to find “AI Slop” before merging the generated code. Claude Code review uses a parallel agentic architecture, dispatching a specialized pod of agents to review simultaneously. A verification agent acts as a lead auditor reviewing the findings from the specialized agents, which in turn, each focusing on logic, edge cases, security, vulnerabilities, dependency integrity and so on. CodeRabbit uses a hybrid architecture that combines a deterministic workflow with targeted two agentic loops and not the swarm. Recently CodeRabbit added the ‘Fix All Issues with AI Agents’ feature, which generates a single structured prompt that can be handed off to any external agent such as Claude Code or Cursor to execute fixes in parallel.
Democratization of Coding
With AI, making it so easy, it decouples the logic from language, its syntax, the drudgery of typing line by line and removing the high barriers of technical fluency. If anyone can clearly specify in natural language what needs to be achieved by the software, the system will build it for them, thus giving rise to the Citizen Architect. Any domain expert, be it a doctor, a scientist, a student or a teacher, an end user or anyone with an idea, a clear idea can get that implemented in days, if not hours using AI.
Viability and cost break even points of many projects across the world would shift and a huge amount of pent up development could be taken up by the enterprises. The technical debt accumulated over decades can be repaid using AI and the legacy code bases be ported to modern languages and architectures easily enabled by this.
The advantages of this ability to generate code at will, are like – anyone with an idea can generate code and need not be a developer, it democratizes the whole development and small, lean teams can accomplish a lot in much shorter time with a lot less money and time. While the AI generated code works (and not work as well or not work as exactly intended!), it has its quirks too along with hallucinations! Let me illustrate that with a simple and trivial example.
Here the issue is very innocuous, but the flow of thinking and thus the possibilities is illustrative. It can for example, hallucinate a non-existent database table. Unfortunately, I cannot post more complex or substantive examples here. As the functionality and size of the code increases, the complexity of issues rise exponentially with it and beyond human comprehension, given the pace at which the code is generated.
So, How Much Code Can AI Generate?
With AI generating code at the speed of tokens, it could be a world full of code. So how much code can a GW data centre generate?
Back of the envelope calculations indicate that a mere GW can generate many times more code than all of the developers can generate, equivalent to the output of half a billion developers! The assumptions in arriving at this number can be challenged, but that should give a magnitude of the volume we are talking about here. Models optimized for code can generate 150 to 200 tokens per Watt-hour and developers generate about 50-100 lines of code per day. Obviously people can debate these ever changing numbers on the side of the machine, while the human rate of output is stagnant. This AI generated code comes at a tiny fraction of human cost.
Half a billion is many times more than all of the developers on earth, and there is no dearth of them, as on date, at 31 millions of them.
China has the largest pool with 7 M and going up to 9.4 M if students and hobbyists are included.
Those numbers for India are like 5.8 M and 17 M including the students and hobbyists. For Europe, it is 6.1 M to 10 M. The US has about 4.4 M of them. However, the kind of work they carry out differs a lot in each region. The US leads the product development, with Chinese developers serving the local eco system predominantly, the Indian developers mostly serving the world and Europe having more senior developers. That number of half a billion is just for a Gigawatt! It does take 3-4 years to put together a gigawatt of a data centre and many gigawatts of data centres are in the making, though not all are for generating the code. However, Anthropic’s Economic Index reports do indicate that about 40-60% of their Claude.ai and 1st party API usage is for the dominant use case of computer and mathematical category i.e. primarily code generation, debugging and architecture, with all other use cases being very diffused and fragmented following that, struggling to break 10% barrier. In markets like India, code-related tasks account for over 50% of all Claude usage, acting as the “anchor” use case that supports the technology’s economic viability.
The Glut of Code
What has this ability led to? This has immediately led to huge code overload, a glut of code everywhere, with enterprises scrambling to deal with it.
The visible brunt is being born by the code repositories of the world – GitHub and GitLab! They no longer host just the human generated code, but have become primary execution environments or repositories for autonomous AI agents. In early 2026, GitHub is processing 14 billion commits per year, a staggering 14-fold increase from pre-AI levels. As of March 2026, over 50% of all code published to GitHub is AI generated, and it is rapidly climbing up. Pull requests (PRs) initiated by AI agents (like Claude Code and GitHub’s own Coding Agent) surged from 4 million in late 2025 to over 17 million per month by mid-2026 (i.e. many times in just a few months). There is 4x increase in code cloning and duplication, putting immense pressure on GitHub’s deduplication algorithms and storage clusters. AI agents can trigger hundreds of commits and CI/CD runs in a single hour as opposed to prolific developers pushing the code 5-10 times a day.
This has led to an aggressive change from the traditional seat-based pricing model to hybrid consumption models of these companies.
GitHub’s original architecture was built for human-scale interaction, not for the vibe coders or swarms of agents. They are also currently in the final, high-pressure stages of migrating its massive legacy backend from their own servers to Microsoft Azure. The Agentic Flood hit exactly during this transition, leading to cascading failures and outages. The outages have doubled to 8-10 major incidents in Q1-2026 when compared half of yester years, with 4 major incidents in March itself. There have been service degradations with AI agents not being able to talk to it, causing CI/CD pipelines stalling globally.
Another platform, GitLab shares many of the same underlying AI Factory led issues and pressures as GitHub. GitLab saw several 20–30 minute blips in March (with 99.58% uptime) as it launched the Duo Agent Platform. Unlike GitHub’s massive multi-hour crashes, GitLab’s issues were more “granular” – specific services like Security Dashboards or MR (Merge Request, yes, they call it with a different name) reviews failing while the core Git service remained up. While GitHub is focused on handling the raw volume of the “Agentic Flood,” GitLab is positioning itself as the “Intelligent Orchestration” platform that focuses on the cost and security of that flood. However, there is interdependency too, with many enterprise pipelines and mirror-repos crossing both platforms, so a crash on one, bottlenecks the other.
Then there was the trend of “TokenMaxxing” with the likes of OpenAI and Meta rewarding their engineers for high token burn, with the highest usage of 281B tokens, reportedly costing over million dollars in spend. Meta’s has recently shuttered this “Claudeonomics” leaderboard.
The Paradoxes of Vibe Coding
What are the dichotomies and paradoxes lurking in here? When the models generate the code, at that pace, humans hardly read the generated code, instead of writing it in the first place.
Thus, the role of the developer has shifted from “writer of code” to “architect of vibes” and “auditor of logic”. The value of a developer is no longer their knowledge of syntax, but their taste, architectural vision, the ability to specify clearly, take right design decisions and spot a subtle bug in a thousand lines of machine-generated code i.e. better or superhuman debugging skills.
Let us contrast this with writing a book vs reading a book. All of us know that writing a book takes a few to many months (ok, that was without AI!) and reading it takes only a few hours, of course, depending on the size of the book. When it comes to reading code as opposed to writing, it is entirely and fundamentally a different process and needless to say it is much harder than reading a book.
Reading a book is primarily a linguistic activity, while reading code is a logical and spatial problem-solving kind of task. The cognitive load is different and in fact the research shows that reading a book and reading code happen in different parts of your brain – the first one activates the brain’s language network and the latter activates the Multiple Demand network, the same area used for math, puzzles and complex logic and it hardly uses language areas at all (though ironically the models which generate code prolifically are still called LLMs).
Code is often read much more often than it is written – attributed to Guido Van Rossum, the creator of Python, highlighting why Python emphasizes readability. There are informal sayings in the industry that it is 10x harder to read than write, but in reality it actually depends on various factors, but suffice it to say it is definitely harder to read code and grasp, than writing it in the first place.
The Paradox of Expertise: The Blackbox Problem
While touted as a way for non-technical people to build software, the reality of it revealed a paradox: Vibe coding requires more engineering expertise, not less, to be done safely.
The Comprehension Gap: When an AI generates 90% of the code or even 100% of it, the human developer often loses track of how the system works. This leads to “Dark Debt”—hidden complexity and bugs that no one understands and that only surface months later. A project might work perfectly for the demo, but when a specific edge case arises in production, the “vibe coder” has no idea where to look in the thousands of lines of machine-generated code. Of course, this is being addressed with AI code reviewers, but the underlying lack of human understanding and comprehension remains. The key paradox here is the loss of interpretability.
Security Risks: Reports found that 45% of AI-generated code in 2025 introduced vulnerabilities, such as SQL injection flaws or hardcoded secrets. Without a senior engineer’s eye to audit the AI’s output, “vibe coded” apps often became security nightmares. As I write this, it is also being addressed with better AI code/security auditors and Anthropic’s Mythos rollout is staggered, given the implications.
Productivity Illusion: Studies showed that while AI sped up simple tasks, it actually slowed down experienced developers on complex tasks (by ~19%) because the time saved writing code was lost debugging subtle AI hallucinations. While AI can generate many times the code of human developers, the end-to-end and overall productivity improvements are more modest in percentage terms, as the bottlenecks in the organization shift elsewhere.
The Paradox of Sovereignty: Distributed vs. Centralized Power
True democratization must imply decentralized power. Vibe coding does the opposite with the dependency of the vibe-giver, in the hands of massive model providers. The power has moved from elite coders, millions of them, to GPU-rich corporations and the investors. It is all about Tokenomics.
The Paradox of Semantic Debt
In traditional software, the technical debt is messy, spaghetti or legacy code. With vibe coding, it is the rise of “Semantic Debt”. Because the user is coding via vibes, imprecise or less precise natural language, the specifications are vague at the level, but the underlying code generated often contains the cruft or the vulnerabilities of edge cases, that the user never intended or is never aware of. As it becomes infinitely easier to generate infinite amounts of code, the software is only “mostly” correct, but a sea of semi-broken or fragile one, that is harder to audit than to build a proper one in the first place.
The Paradox of Value: Commoditization of the Developer and Software
If everyone is a developer, paradoxically the value of being a developer or the software approaches zero. Ironically, vibe coding or AI actually empowers the senior architect more and better than a novice. So instead of levelling the playing field, vibe coding force multiplies the power of who understand the system design. So a novice can become a better hobbyist, the elite expert or small groups can become a 1-person or lean conglomerates. The new or entry level developer used to learn over time and graduate to the experienced and higher skilled designer and architect. With AI and the pressure to shore up the bottom-line, the entry level jobs will be hard to come by and there is already some statistical evidence for this. As a result, this pipeline of software engineering leadership breaks and new ones will need to be established to get those elite members of the industry. While the models are trained fast with synthetic data, ouroboric loops can result in model collapse and the frontier labs fight these pitfalls.
So Vibe Coding can generate a significant amount of technical debt, if rushed too soon, at the same time addressing or repaying the traditional, accumulated debt in certain areas such as modernizing the legacy code faster or enabling those Enterprise technical and architectural overhauls, hitherto not possible. While it lowers the barriers for startups or anyone with an idea to rush with an implementation at a fraction of cost and time, precisely the same thing increase the competition in the overall landscape, with many more turning out their ideas into products and entering the market. Copyright for the code can lose its significance and open source can have newer meaning and purpose.
Part V: The Changing Landscape of IT Services and Jobs Forced by AI follows..
Part III – The Infrastructure Arms Race: Giga-Scale Economics
By Bhanu Nallagonda, Cofounder, Ogha Technologies
March ‘26
If the economics of AI are abstract, the physical manifestation of the industry in 2025 is concretely, overwhelmingly massive. The race to AGI has morphed into a race for gigawatts. The era of the megawatt data centre ended in 2024 and 2025 clearly started the era of the Gigawatt Campus.
The Giga-Projects: Redrawing the Map
Tech giants are no longer building data centres; they are building cities of compute.
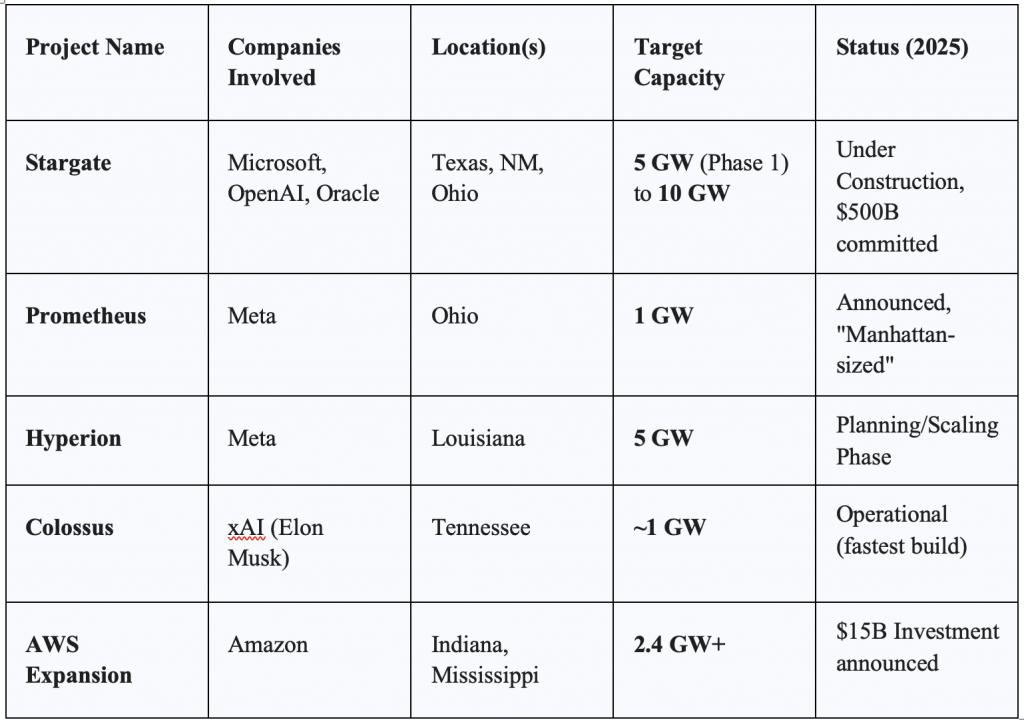
Project Stargate (Microsoft/OpenAI)
The most ambitious of these projects is “Stargate,” a $500 billion infrastructure initiative. By late 2025, OpenAI and Microsoft, in partnership with Oracle and SoftBank, were developing five new sites across the US (Texas, New Mexico, Ohio, and the Midwest).
Scale: The project targets 10 gigawatts of capacity. For context, a typical nuclear reactor produces about 1 gigawatt (alright, we are going to have SMRs, Small Modular Reactors as well). Stargate is essentially building an energy infrastructure equivalent to ten nuclear power plants solely for AI.
Strategic Importance: This project is designed to house millions of next-generation GPUs, including the forthcoming Nvidia Rubin architecture. It represents a bet that compute power is the ultimate commodity of the 21st century.
Subsequently it underwent some changes and OpenAI reportedly scrapped its plans to own and build its own dedicated data centers. Its flagship site at Texas is partially operational and others are in various stages.
Meta’s Prometheus and Hyperion
Not to be outdone, Meta announced its “Prometheus” supercluster in Ohio (1 GW) and the “Hyperion” cluster in Louisiana, designed to scale to 5 GW! Mark Zuckerberg described these facilities as having the “footprint of Manhattan”, a physical testament to the company’s pivot to “Superintelligence Labs”. Unlike Microsoft’s cloud-focused approach, Meta’s infrastructure is largely dedicated to training its open-source Llama models and powering its consumer AI products. While OpenAI and Microsoft pivoted to renting, Meta is still doubling down on owning.
Amazon and Google
Amazon Web Services (AWS) committed to a 2.4 GW expansion in Indiana alone, part of a $15 billion investment plan for the region. Google, meanwhile, aggressively acquired power infrastructure, buying Intersect Power for $4.75 billion to secure clean energy for its AI loads.
The Energy Bottleneck and the Nuclear Pivot
The sheer energy density of these projects has collided with the realities of the power grid. In 2025, data centres are projected to consume significant percentages of national electricity output in countries like Ireland and regions like Northern Virginia. This has forced a radical diversification of energy sourcing.
The Nuclear Renaissance: To bypass grid congestion, tech giants turned to nuclear power. Microsoft inked a historic deal to restart Three Mile Island Unit 1, effectively buying the plant’s entire output for decades. Simultaneously, OpenAI-backed Oklo pushed forward with plans for Small Modular Reactors (SMRs), aiming for deployment by 2027-2028. Oklo has received its initial regulatory approvals this month. The Department of Energy (DOE) has set a target for Oklo to achieve criticality (a self-sustaining nuclear reaction) at its pilot reactor by July 4, 2026. Oklo’s stock price has corrected a lot in the meanwhile.
Gas as a Bridge: With nuclear projects taking years to spool up, the immediate demand is being met by natural gas. “Behind-the-meter” gas plants—turbines installed directly at the data centre site—became the standard for rapid deployment. xAI pioneered this approach with its “Colossus” cluster, using rented gas turbines to bring 100,000 GPUs online in months rather than years.
The Infrastructure Giga Projects of 2025
Gigawatt Data Centre Economics
Here is a quick back of the envelope calculation for a GW AI data center:
Building a GW facility requires approximately $50 B of upfront capital with estimates varying from 35 to 60 billions of US dollars. With the latest Nividia’s Vera Rubin (GB300) clusters, it can go up to $65B as well!
Out of this, the lion’s share of 45% or more (48% for Vera Rubin) can go to the compute or GPUs.
Construction and Cooling takes about 25% of the capex, for specialized liquid cooling and lower for air cooling.
Electrical and Infrastructure costs about 20-23%.
High bandwidth Networking requires about 7-10%, with higher percentage for a million+ GPUs
Monthly Opex could touch a billion dollars or about 12B dollars per annum, including the depreciation with a 5-year replacement cycle. Incidentally, power transmission fees have gone up globally in 2026. Obsolescence rates are very high causing nervousness, but there are also instances where they can plod on. There are higher obsolescence rates when performance improvements are made, for e.g. performance-per-watt of a 2026 Vera Rubin chip is nearly 50x that of a 2023 Hopper chip, so facilities “plodding on” with older gear become too expensive to run relative to the tokens they produce!
With an estimated annual throughput of 1.6 quadrillion tokens per annum at 70% utilization, the production cost per million tokens would be about $7.
However, there are many variants that come into picture, with the input costs brought down with various optimizations, efficient compute, better models, extending the life (older TPUs are still not shut down due to high demand for compute) and so on. It may not be profitable for commodity/consumer chats, but for high value reasoning models and enterprise use cases.
Specialized hardwired chips/ASICs can bring this cost down to below a dollar. The companies which have the full stack – processors, models, data centres, software eco-system, applications are going retain much of the profit of all the layers, with the lion’s share being at the heart, the chips.
On February 1, 2026, in the Budget speech, the Finance Minister Nirmala Sitharaman introduced the most aggressive digital infrastructure incentive in India, by offering a tax holiday until 2047, for any foreign company providing cloud services (SaaS, IaaS, PaaS) to global customers using the data centres located in India and their global revenue will be exempt from Indian income tax until the year 2047. To qualify, the foreign entity must serve its global clients from Indian soil and the tax holiday is only available to those using “MeitY-notified” data centres. However, any revenue earned from Indian customers must be routed through a local Indian reseller entity, which remains subject to standard Indian corporate tax. This move has fundamentally changed the math for hyperscalers (such as Amazon, Google, Microsoft, Meta) and colocation providers (Equinix, Digital Realty, Yotta etc.). Before the budget there were about $70B worth of projects in pipeline and after the budget about $90B were recorded. The tax holiday makes India more attractive than the traditional hubs like Singapore, which faces land/power constraints or Dublin.
Crowding-out Effect on Funding
There has been a significant “Great Reallocation” of capital and the definition of a “venture-scale” startup has shifted. The massive CapEx for Giga scale projects has created a polarized investment landscape with AI startups captured 35% of all global venture capital in the most recent funding cycle. Investors have largely stopped funding “AI wrappers” (simple apps built on top of LLMs). Instead, the money is flowing into Infrastructure (power, chips, data centres) and Vertical AI (highly specialized models for law, medicine or engineering). High-interest borrowing by the biggies has also tightened the overall credit market, making it harder for small, non-AI startups to get cheaper loans.
However, AI is accelerating and helping the scientific discoveries much more rapidly. A few examples are given here:
In mid-March 2026, the collaboration between Google DeepMind, NVIDIA and EMBL-EBI achieved a milestone that has been called “the completion of the biological periodic table”. While AlphaFold 2 predicted the shape of a protein, AlphaFold 3 (running on NVIDIA’s latest Blackwell clusters) predicts the interaction. It can model how a protein binds to DNA, RNA and ligands (small molecules). For the first time, researchers can see the “lock and key” mechanism of viral entry into human cells in 3D before doing a single wet-lab experiment. This is the Human Interactome—a map of every conversation occurring between molecules in our bodies.
The massive investments in compute are also fundamentally changing the Probability of Technical Success (PTS) in medicine. Traditionally, finding a ‘lead compound’ i.e. a potential drug candidate took 3–5 years. In early 2026, AI-native bio-techs like Isomorphic Labs and Insilico Medicine have started consistently hitting this milestone in 13–18 months. Multiple AI-designed drugs for Idiopathic Pulmonary Fibrosis (IPF) and Solid Tumors are in Phase III trials right now. If these succeed by late 2026, it will prove that AI doesn’t just find more drugs, but better drugs that are less likely to fail in humans.
AI is now used to “twin” patients (digital twin!) – creating digital models of how a specific person might react to a drug based on their genome, which is helping to optimize clinical trial enrolment and reduce the “90% failure rate” that has plagued pharma for decades.
The University of New Hampshire (UNH) breakthrough, published in Nature Communications in February 2026, represents a fundamental shift in how we “mine” human knowledge to solve physical engineering problems, by building the Northeast Materials Database (NEMAD),a repository of 67,573 magnetic compounds and thereon researchers identified 25 entirely new high-temperature magnets.
Traditional magnets lose their “pull” as they get hot. For an EV motor or wind turbine, a material must stay magnetic at temperatures exceeding 150°C to 200°C. The 25 new compounds identified by the UNH AI were specifically selected because they maintain their magnetic properties at these extreme thresholds. Currently Neodymium is used. Extracting rare earths is infamously toxic and they geopolitical significance.
While the specific chemical formulas of the 25 new compounds are currently being shielded for patent and further testing, early data suggests they utilize more abundant elements like Iron, Cobalt, and Manganese in unique crystal geometries that mimic the strength of rare earths without the actual rare-earth atoms. Traditionally, discovering these 25 materials would have required 50 years of trial-and-error lab work. The AI did it in weeks by “reading” decades of unstructured scientific papers and predicting which combinations humans had missed.
While the AI discovery is a massive leap, the materials must now survive the “Valley of Death” between a database and a factory. So the funding has specialized with generic software startups struggling to find capital and deep tech startups that combine AI with biology, materials, robotics or other real world areas more effectively are receiving the largest Series A and B rounds in history.
Next Part IV: Vibe Coding and the Paradox of Democratization
Part II – The Economics of Intelligence: A Tale of Two Curves
By Bhanu Nallagonda, Cofounder, Ogha Technologies March ‘26
The financial dynamics of AI in 2025 were characterized by a dramatic divergence between the unit cost of intelligence and the aggregate cost of deployment. Understanding this paradox is essential to grasping the market forces shaping the industry.
The Training vs. Inference Cost Curve
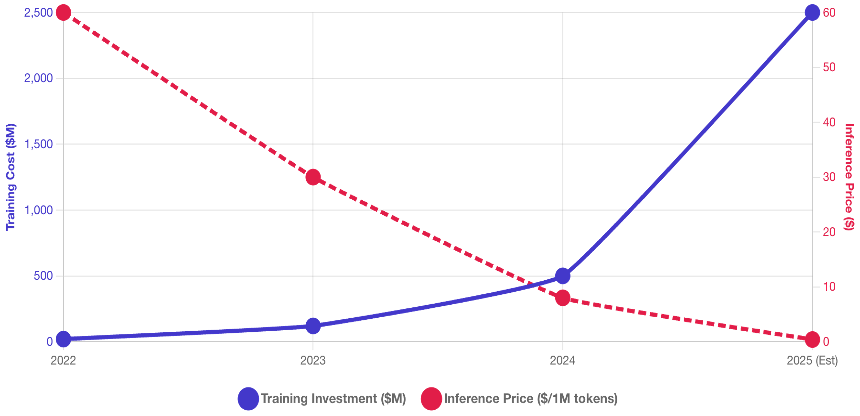
For years, the industry spotlight was fixed on the astronomical costs of training foundation models – billions of dollars spent on GPU clusters to create a GPT-4 or Gemini or Claude. Their plans extend to spending trillions of dollars over the coming years. However, 2025 marked the definitive shift where inference (the cost of running the model) became the dominant economic factor.
The Plummeting Cost of Inference
The unit cost of intelligence dropped precipitously. According to the Stanford AI Index 2025, the inference cost for a system performing at the level of GPT-3.5 dropped over 280-fold between late 2022 and late 2024.This deflation was driven by a confluence of factors:
Algorithmic Optimization: Techniques like Sparse Activations (Mixture of Experts) allowed models to activate only a fraction of their parameters for any given token, drastically reducing the compute required per operation. Furthermore, distillation—teaching smaller models to mimic larger ones—allowed enterprise-grade performance on much lighter architectures.
Hardware Efficiency: The deployment of specialized inference chips and improved GPU architectures (like Nvidia’s Rubin platform) reduced the energy-per-token cost by roughly 30-40% annually.
Price Wars: Intense competition among model providers and aggregators like OpenRouter drove consumer-facing prices down to commodity levels. Developers could now shop for the cheapest intelligent token across dozens of providers.
The “Inference is the New Margin Killer” Paradox
Despite the collapse in per-token prices, enterprise spending on inference exploded. Industry reports from 2025 indicate that 60–80% of an AI system’s total lifecycle cost is now incurred during inference, not training. This trend is driven by three primary mechanisms:
Jevons Paradox: As intelligence became cheaper, demand for it spiked. Developers stopped rationing tokens and began building applications that consume them voraciously.
Agentic Loops and Token Creep: The shift to agentic AI means that a single user request (e.g., “plan a travel itinerary” or “build this whole website or app”) might trigger hundreds or thousands of internal model calls. The agent might search the web, verify the results, draft an itinerary, critique the itinerary, refine and rewrite it—all before the user sees a single word. A simple task that once costed one unit of inference now costs hundreds. Furthermore, RAG (Retrieval-Augmented Generation) systems stuff vast amounts of corporate data into the model’s context window for every query, multiplying the token count per interaction.
The “Autoscaling Tax”: The requirement for low-latency responses forces companies to keep GPUs “warm” and available 24/7. Unlike training, which is bursty and schedulable, inference demand is unpredictable, leading to utilization inefficiencies that can bloat costs.
Token Usage and The 100 Trillion Milestone
The volume of data processing in 2025 reached staggering levels. OpenRouter, a leading model aggregator, reported processing over 100 trillion tokens by mid-2025, with daily volumes exceeding 1 trillion tokens. To put this in perspective, this daily volume rivals the entire monthly throughput of major providers from just two years prior.
This growth is not merely a function of more users, but of heavier users. The fastest-growing behaviour on these platforms is “agentic looping” where models talk to models. This shift toward machine-to-machine communication suggests that in the future, the vast majority of AI text generation will never be read by a human—it will be read by other AIs as part of an intermediate processing step.
The Shift to Agentic AI — From Chat to Action
If 2025’s infrastructure was about size, its software trend was about being agentic. The industry consensus is that the era of the “chatbot”—a passive responder to human queries—is ending. It is being replaced by Agentic AI.
From “Prompt Engineering” to “Outcome Engineering”
The core shift in 2025 was from Generative AI (creating content) to Agentic AI (executing workflows). This transition, often termed “The Age of Autonomy,” involves models that can reason, plan and use tools to achieve high-level outcomes.
Outcome Engineering: The skill of “prompt engineering” (crafting the perfect text string) began to fade. It was replaced by “outcome engineering”—defining the parameters of success and allowing the agent to figure out the “how”. Users stopped asking models to “write code for a login page” and started asking them to “build a login system that integrates with Auth0 and handles these specific edge cases.”
The Unit of Work: In a chat paradigm, the unit of work is a “turn” of conversation. In an agentic paradigm, the unit of work is a “job”—booking a shipment, refactoring a codebase, or auditing a financial statement.
Swarm Intelligence and Frameworks
The “Single God Model”—one massive LLM doing everything—proved inefficient for complex tasks. 2025 saw the rise of Swarm Intelligence and multi-agent orchestration.
Specialization: Frameworks like Microsoft AutoGen, LangGraph and CrewAI allowed developers to build teams of specialized agents. One agent might be the “Researcher”, another the “Writer” and a third the “Critic.”
The “Critic” Loop: This collaborative approach was found to significantly reduce hallucinations. A “Critic” agent could catch errors made by the “Writer” before the human ever saw them, creating a self-correcting loop that mimicked human peer review.
Adoption Reality: Despite the hype, true autonomy remains rare. While 62% of companies experimented with agents, only a fraction (estimated 15-20%) had autonomous agents in production by year-end.The industry was stuck in “Pilot Purgatory”, struggling to trust agents with unsupervised execution of critical tasks.
The “Circular Economy” and the AI Bubble
A shadow looming over the 2025 AI landscape is the financial structure supporting this explosive growth. Analysts have identified a “circular funding loop” that resembles the vendor financing schemes of the dot-com era, raising concerns about a potential asset bubble.
The Anatomy of the Loop
The mechanism, as detailed in financial reports from late 2025, operates as follows:
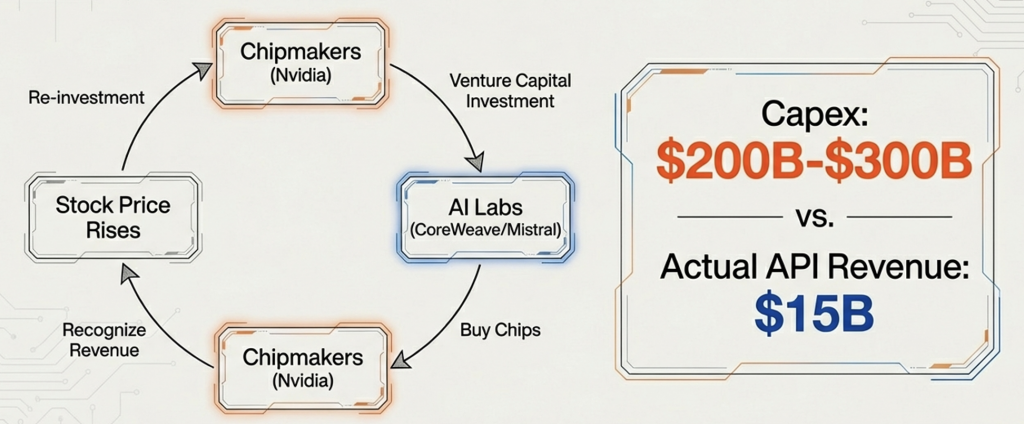
Chipmakers Invest: Companies like Nvidia invest billions of venture capital into AI startups and labs (e.g., OpenAI, CoreWeave, Mistral).
Labs Buy Chips: These startups use the investment capital to purchase massive quantities of hardware (GPUs) and cloud services.
Revenue Recognition: The chipmakers and cloud providers (Microsoft, Oracle, Nvidia) recognize these purchases as revenue, boosting their stock prices.
Reinvestment: The boosted valuations allow for further investment and borrowing, continuing (or perpetuating!) the loop.
Critics argue that this creates “artificial” revenue. For instance, Nvidia’s investment in OpenAI is effectively Nvidia bankrolling its own future sales. This creates a “merry-go-round” of capital that inflates revenue figures without necessarily reflecting genuine, organic end-user demand.
Market Jitters
By late 2025, this fragility began to manifest in the markets. While the S&P 500 remained strong, Nvidia’s stock experienced volatility as investors questioned the sustainability of the $200-300 billion annual rise in AI capital expenditures.The disparity between infrastructure spend i.e. Capex and actual AI revenue (approx. $10-15 billion in pure API spend) remains the primary risk factor for 2026. If the startups fail to generate real-world revenue from end-users (read as SaaS income, not SaaSopacalypse, more on it later again) sufficient to cover these hardware costs, the cycle could unravel. As a proof point, recent financial disclosures and internal documents leaked in February 2026 verify that OpenAI has significantly revised its long-term revenue guidance upward by 27% while simultaneously reporting a contraction in profit margins due to surging operational costs. Against the earlier investor target of 40% of margin, it shrunk to 33% in the latest report for 2025 from 40% in 2024 despite the revenue growth. While this could be due to last minute purchase of premium compute to meet the token usage above expectations or estimates, the math of growing usage and reducing inference costs are not exactly helping the margins.
Majority of the revenues still come from the APIs. The revenues are multiplying or growing at a very fast clip year over year, yet they are much smaller at the moment for the investments being made. OpenAI says it’s on pace to generate $25 billion in revenue this year, versus Anthropic’s $19 billion, while their latest ARRs as of March ’26, are only at $5.2B and $1.8B respectively. So they need to grow many times, as many as 5x to 10x this year, in 2026!
Interestingly, Apple seems to be swimming against the tide (or are they languishing?), with a drastically lower capex spend when compared to the AI infra super spenders, though it did increase its capex year over year by about 35%. Apple’s share price correlation to Nasdaq-100 has hit the lowest in 20 years as per Bloomberg. They have licensed massive 1.2 T parameter mode from Google at about 1 B USD per annum, while hosting it in its own private cloud compute infrastructure.
At this layer, the risk takers are capable, deep pocketed, well funded and aware to a large extent. So though the investments are heavy and disproportionate, any failures will effect ruthlessly those, who are not strong enough to weather these or who bet the last penny unscrupulously. Would any of those be catastrophic?
‘Part III – The Infrastructure Arms Race’ follows…
Part I – The Model Landscape: The Frontier of Reasoning
By Bhanu Nallagonda, Cofounder, Ogha Technologies March ‘26
The relentless march of model performance continued in 2026, but the metric of success shifted irrevocably. In previous years, the vibe of a model was its fluency, creativity and the ability to hold a conversation was the primary differentiator. In 2025, the industry pivoted hard toward reasoning and utility. The landscape changed from “Can it write a poem?” to “Can it debug this repository, plan a logistics route and execute the API calls without hallucinating?”
The Titans: A Comparative Analysis
The release cycle of the AI Titans was dominated by the intensification of the rivalry between the primary research labs—Google DeepMind, OpenAI and Anthropic—along with the surging capabilities of open-weight contenders that have fundamentally altered the competitive landscape.
Google: The Gemini 3 Era
In 2025, Google successfully shed the perception of being a “fast follower” and reasserted its research dominance with the release of the Gemini 3 family. Unlike its predecessors, which were defined primarily by their native multimodal architecture, Gemini 3 was defined by “big leaps in reasoning” and efficiency.
The Gemini 3 Pro model demonstrated that improvements in agentic capability could be decoupled from massive parameter scaling. Instead, Google focused on architectural refinements that allowed for better decision-making in multi-step workflows. This “reasoning-first” approach allowed Gemini 3 to excel in scientific domains, boosting breakthroughs in genomics (in gene editing, disease interpretation and drug discovery etc.) and quantum computing (helping develop expert level empirical software). Furthermore, the introduction of Gemma 3 continued Google’s aggressive push into the open-model space, offering developers powerful local inference capabilities that rivalled the previous year’s frontier models, effectively commoditizing “GPT-4 class” intelligence for local devices.
OpenAI: The Bifurcation of Intelligence
OpenAI’s strategy in 2025 diverged into two distinct lineages, acknowledging that “creative fluency” and “logical reasoning” might require different architectures, while continuing its consumer focus.
If GPT-5.2 was the apex of fluid conversation, GPT-5.4 is the ‘current’ undisputed master of autonomous execution. It is the first flagship to successfully unify the ‘thinking’ depth of a reasoning model with the ‘doing’ agility of a specialized agent. By scoring a record 83% on the GDPval benchmark across 44 professional occupations, it has effectively moved beyond being a ‘super-spellcheck’ to becoming a digital specialist in law, finance, and engineering. While there were some rumours of 2M token context window, it debuted with a 1M long context window, effectively eliminating the need for complex RAG (Retrieval) workarounds in 90% of use cases. GPT-5.4 doesn’t just write code; it operates the computer. It can navigate a desktop environment, use a mouse and keyboard to interact with non-API legacy software, and perform multi-step workflows across different applications with a 75% success rate on OSWorld-Verified—surpassing the measured human baseline. It can extend the lifetime of these legacy software, while competing for the ‘seat’ of a Junior Investment Analyst or a Staff Engineer. Just to elaborate, Google’s Gemini’s score was based on earlier terminal based benchmarks and humans score 72.4 on this (for whatever be the reasons) and Claude 4.6 Sonnet at 72.5, a shade above the humans!
The o-Series (o1, o3, o3-mini): The real paradigm shift, however, was operationalized by the o-series. These models introduced the concept of “test-time compute” or “thinking” phases. When asked a complex math or coding problem, o3 does not simply predict the next token. It generates hidden chains of thought, exploring multiple logical paths, verifying its own assumptions and backtracking if it detects an error, before finally outputting a response. This “System 2” thinking significantly reduced hallucination rates in high-stakes tasks.
Anthropic: The Enterprise Workhorse
Anthropic continued to cultivate its reputation for safety and reliability, a positioning that paid dividends in the enterprise market. The Claude 4.5 series, particularly Claude Opus 4.5, emerged as the heavy lifter for complex engineering tasks.
Beyond Coding Dominance: While Claude Opus 4.5 conquered the ‘contamination-free’ benchmarks, Claude Opus 4.6 Thinking has redefined the ‘contamination-free’ organization. It is no longer just solving GitHub issues; it is managing them. By introducing Adaptive Thinking—a native reasoning layer that self-scales its ‘effort’—and a massive 1 million token context window, Opus 4.6 has become the gold standard for full-repository refactoring. It is the first model to score a staggering 80.8% on SWE-bench Verified, effectively ending the era of ‘file-by-file’ coding in favor of ‘system-wide’ orchestration.
Contextual Mastery: Its massive context window and superior instruction-following capabilities made it the preferred engine for many enterprise agentic frameworks.
So it is becoming rather obvious that different leaders are pursuing different objectives, which is a good thing and that also makes not directly comparable, perhaps more so in future if they diverge more in their paths, leaving the user to choose what is best suited for their task on hand.
The Open-Weight Insurgency
Perhaps the most disruptive trend of 2025 was the compression of the performance gap between proprietary (closed) and open-weight models. Stanford’s AI Index Report 2025 highlighted that the performance difference on some benchmarks shrank from a significant 8% to a negligible 1.7% within a single year.
There are allegations that models gaming the benchmarks with distillation, so while their benchmark performance is excellent, the real world performance is not at the same level (Vibe Divergence). There is some truth in this and most of the models use synthetic data generated by frontier models for finetuning through distillation.
Models like Llama 3.3, DeepSeek-V3 and Qwen 3 provided enterprise-grade performance at a fraction of the cost. DeepSeek-V3, in particular, stunned the industry by offering performance parity with GPT-4 in coding tasks while being available as free download, forcing closed providers to compete on service, reliability and extreme-frontier capabilities rather than raw intelligence alone.
The Crisis of Measurement: Benchmarking
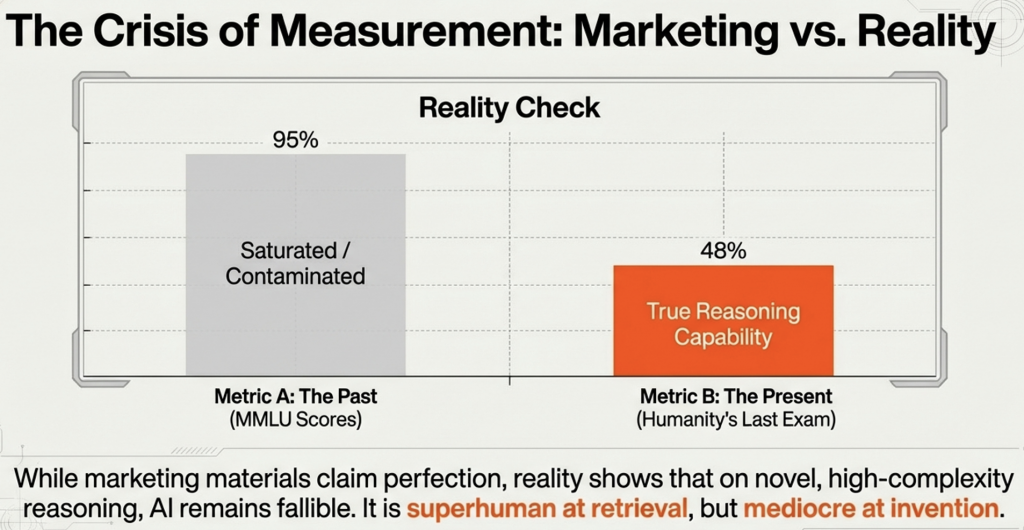
As models saturated traditional benchmarks like MMLU (Massive Multitask Language Understanding) with scores nearing 90%+, the industry faced a crisis of measurement. “Contamination”—the phenomenon where models memorize test questions present in their training data—rendered many classic benchmarks useless. In response, 2025 saw the rise of “living” benchmarks designed to be un-gameable.
LiveBench and Humanity’s Last Exam
The inadequacy of static benchmarks led to the adoption of LiveBench and “Humanity’s Last Exam” as the new gold standards for frontier evaluation.
Methodology: Sponsored by Abacus.AI, LiveBench introduced a regime of regularly released, new questions with objective ground-truth answers. This design specifically limits potential contamination, as the questions did not exist when the models were trained.
The Reality Check: On these rigorous tests, the gap between the absolute frontier and the “efficient” tier became starkly visible. While marketing materials claimed near-perfect scores, reality showed that on the hardest tasks, even the best models struggled. Gemini 3 Pro and Kimi K2 Thinking led the pack on Humanity’s Last Exam, but with scores only in the 45-50% range. This sobering data revealed that while AI is superhuman at retrieval, it remains fallible at novel, high-complexity reasoning.
SWE-Bench: The Coding Crucible
For software engineering tasks, SWE-Bench Pro became the definitive arena. Unlike simple coding contests (like HumanEval), SWE-Bench evaluates a model’s ability to navigate a complex, multi-file repository and fix a specific issue—a task representative of a real software engineer’s daily work.The New Ceiling: By late 2025, Claude Opus 4.5 and Gemini 3 Pro were trading the top spot, achieving resolution rates around 43-46%. While this represents a massive leap from the single-digit success rates seen in 2023, it also highlights that more than half of complex software engineering tasks still require human intervention.
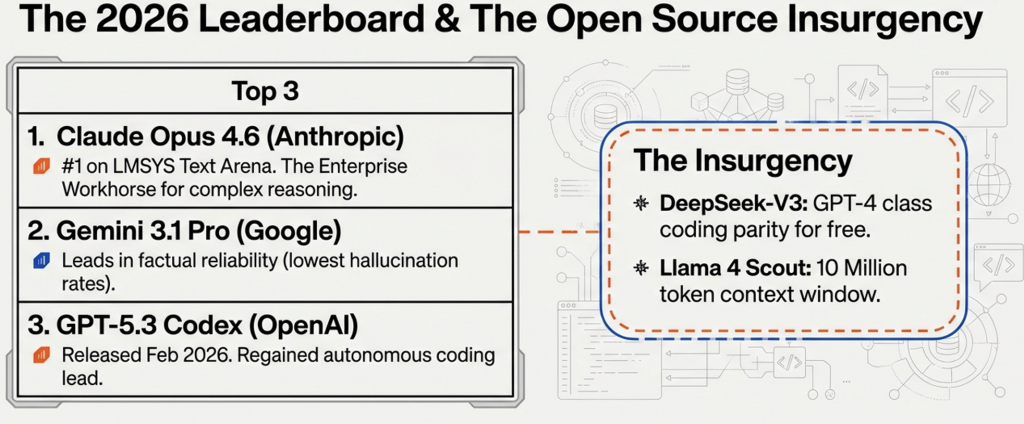
The Frontier Model Leaderboard
Rank
Model
Provider
Benchmark/Signal Highlight
1
GPT-5.4 Thinking
OpenAI
75% on OSWorld-Verified; First model to exceed human baseline in native computer-use.
2
Claude Opus 4.6 (Thinking)
Anthropic
80.8% on SWE-bench Verified; Leader in multi-agent orchestration and architectural refactoring.
3
Gemini 3.1 Pro (Preview)
Google
77.1% on ARC-AGI-2; Highest verified score in novel logic and pattern inference.
4
Grok 4.1 Thinking
xAI
1483 Arena Elo; Holds #1 in human preference for creative and “unconstrained” reasoning.
5
Kimi K2.5 Thinking
Moonshot AI
#1 for Agent Swarm; Can orchestrate up to 100 concurrent sub-agents for massive parallel tasks.
6
Seed 2.0 Pro
ByteDance
89.5 on VideoMME; Dominates in professional video understanding and temporal reasoning.
The key aspect of the leader board is that the leadership keeps changing with each of the leading players releasing their latest and greatest model and shuffling the deck. I confess that I needed to revise this table as I write this in March 2026.
Another aspect is that the time a model spends at the top of the leadership board is also shrinking as the competition intensifies and more capable models are released regularly and more frequently and there does not seem to be a finish line for this race anytime soon. Needless to say, the contents of above table could change between the time I write this and you read it.
However, there are no new players breaking into the ranks of top 3 and it could become increasingly difficult to do so, but let us not rule out any breakthroughs so soon.
As of early 2026, Hugging Face hosts over 2.1M models. The community reached the 1M model milestone in mid 2024. So the growth rate or the ferocity of the number of models can be estimated.
The number of truly frontier class models would be about 50 as of the writing.
While there are a much smaller number of notable and a few original foundational models, there are millions of variants. Then there are unknown number of private models and internal fine tunes.
Comparison of Model Tiers (Feb 2026)
Model Tier
Estimated Count
Key Examples
Frontier Models
< 50
GPT-5.2, Claude 4.5, Gemini 3
Notable Models
~4,000
DeepSeek-V3, Llama-4, Mistral-Next
Open-Source (Public)
2.1 Million+
Hugging Face Repositories
Private Enterprise
~12–15 Million (estimated)
Proprietary internal tools
Natural Language Processing Models dominate the landscape with about 58-60% of share. Computer Vision Models are the next with ~20%. Audio and Speech models about 15% and finally Multimodal and others forming the rest i.e. about 5-6%. The fastest growing models are the Agentic and Reasoning models followed by Vision Language Models (VLMs).
Company-Specific Roadmaps
Company
Flagship Model (2026)
Strategic Focus & Current Pursuit
OpenAI
o3 / o4-mini / GPT-5
The AI Super-Assistant: Moving toward a unified “Frontier” model that acts as a primary interface for all digital tasks. Investing heavily in custom silicon to lower inference costs.
Google
Gemini 3 (Pro/Ultra)
The Personalized Ecosystem: Deep integration with Google Workspace and Chrome. “Auto Browse” features allow Gemini to book tickets and manage travel natively within the browser.
Anthropic
Claude Opus 4.6
Trust & Computer Use: Doubling down on “Computer Use” (Claude moving the mouse/clicking buttons) and legal/financial “High-Stakes Reasoning” where auditability is non-negotiable.
Meta
Llama 4 (Scout/Maverick)
The Open Infrastructure: Maintaining the open-source lead. Llama 4 uses a sparse MoE architecture with a 10M context window to enable self-hosting for massive enterprise RAG systems.
OpenAI: From Monolith to Portfolio
OpenAI has abandoned the “one model for everyone” approach. Their 2026 roadmap features GPT-5.2 for premium knowledge work and gpt-oss (open-weight) models to defend against Meta. They are also testing “AI Inboxes” and “Search AI Mode” that checkout shopping carts directly via a Universal Commerce Protocol.
Google: “Agentic Vision” & Personal Intelligence
Google’s Gemini 3 Flash now features “Agentic Vision.” Unlike passive snapshots, the model “explores” an image or video to find tiny details, drastically reducing hallucinations in visual tasks. Their focus is on Personal Intelligence – connecting to your Photos, Gmail, and History to become a “partner who is already up to speed”.
Anthropic: “Computer Use” & Agentic Coding
Anthropic is the leader in Autonomous Software Engineering. Their report on “Agentic Coding” shows Claude-based agents refactoring 12.5 million lines of code in 7 hours with 99.9% accuracy. They are pursuing “Foundry” – a platform where agents operate with sovereign-level trust and governance.
Meta: Llama Models and massive context window
Llama 4 Scout model, released by Meta on April 5, 2025, officially supports a 10-million-token context window. This was a significant technical milestone, making it the first publicly available open-weight model to offer such a massive capacity – surpassing rivals like GPT-4o (128K) and Gemini 1.5 Pro (2M) at its launch.
The Llama 4 family consists of different models with varying context capabilities:
Llama 4 Scout (109B total / 17B active): Features the full 10 million token window.
Llama 4 Maverick (400B total / 17B active): Supports a 1 million token window.
Llama 4 Behemoth (2T total / 288B active): Announced as a flagship “teacher” model capable of even more complex reasoning, though initially released in preview for research.
Pushing the Frontier in 2027
By 2027, the focus is expected to shift toward Mechanistic Interpretability (understanding why a model thinks) and Verifiable Rewards. This will allow AI to be used in high-risk zones like autonomous surgical assistants or grid-level energy management where “black box” logic is currently a legal blocker.
Mechanistic Interpretability is considered a core pillar of transparent and explainable AI (XAI).
Part II – The Economics of Intelligence: A Tale of Two Curves follows..
The Age of Autonomy, The Infrastructure of Gigawatts and The Paradox of Intelligence
As the AI related voices and noise grew louder and louder, I felt it is pertinent to sit down, take a hard look at it and assimilate the progress so far and figure out where the things are headed, so that we can be where the puck is going to be and not where it has been or is currently. The key questions are the status of the frontier models, AI bubble, vibe coding and its impact, changes to the IT services landscape, threat to the jobs and the AX. The main objective is to scratch the surface and not be swayed by all the hype surrounding it. This blog is divided into multiple parts to make it an easier read. It provides an exhaustive, 360-degree analysis of the state of Artificial Intelligence as we speak. We will dissect the technical breakthroughs of the models, analyze the plummeting cost curves of inference, map the sprawling infrastructure of the AI arms race, explore the sociological shifts brought about by “vibe coding”, look at the strategies being adopted by the traditional IT industry to cope up with these transitions and assuage the investors’, students’ and the entry level developers’ anxiety. Finally, we will extrapolate these trends to figure out where it is all going, how it would reshape the industries, players and the startup eco system. All opinions expressed are personal. The pictures are generated by my co-founder, Kiran using AI tools apart from being a critique.
Introduction
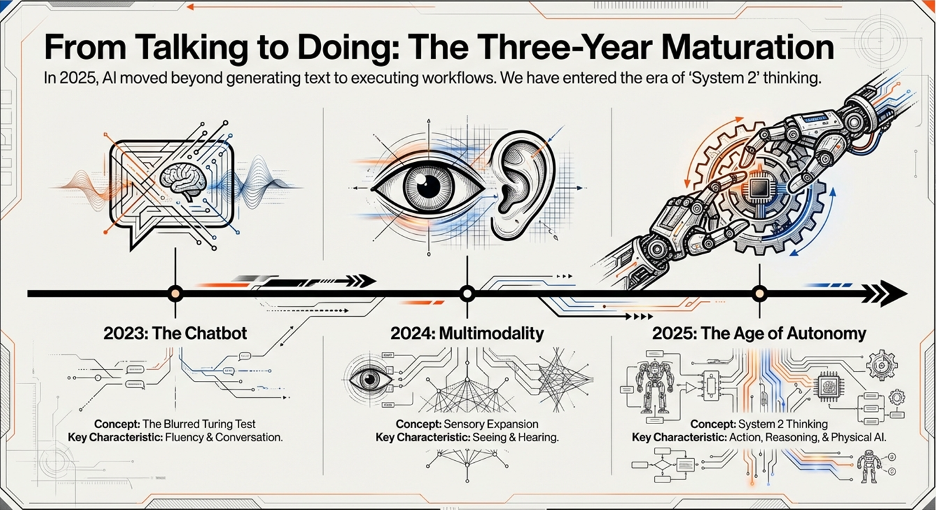
The year 2025 will perhaps go down in the history of computing as the year that saw AI’s fundamental maturation. 2023 saw the advent of the “Chatbot”, a kind of crossing the blurred line of Turing Test, but firmly, and following that 2024 was the year of “Multimodality” – where models learned to see and hear. 2025 has brought in the “Age of Autonomy”, the year when artificial intelligence started acting, beyond just talking. Physical AI and world models have started chalking out their own paths in the meanwhile.
During the twelve-month cycle of 2025, the industry has navigated extreme contradictions. We have witnessed the raw intelligence of frontier models shattering benchmarks that were considered “impossible” merely a few months ago, with systems like Google’s Gemini 3 (and 3.1 Pro this year) and OpenAI’s GPT-5.2 (and 5.3 and 5.4 subsequently this year) demonstrating reasoning capabilities that rival human experts in narrow domains. Of course, the earlier benchmarks themselves got saturated paving way for new ones. More on it later. Simultaneously, the industry is grappling with a profound economic paradox: the unit cost of raw intelligence has plummeted by nearly three orders of magnitude, while the capital required to train a new model skyrocketed into billions and the aggregate cost of deploying enterprise AI also going up manyfold, driven by the voracious appetite of agentic workflows and “swarm” architectures. The paradox does not end there, many reports point now that more than 60% of AI system’s total lifecycle costs come from inference, not training! The share of inference would go up with increasing adoption, despite the cost of inference coming down and the cost of new models skyrocketing with predominant brute force approaches with an eye on AGI. It is also desirable that the usage goes up with real business benefits so that the huge investments made are paid back.
Training vs Inference Costs
The physical manifestation of this digital revolution has become impossible to ignore. The race to Artificial General Intelligence (AGI) has morphed from a battle of algorithms into a battle of gigawatts. We are witnessing the construction of “giga-scale” infrastructure projects—like the $500 billion “Stargate” initiative and Meta’s “Prometheus” supercluster—that rival the industrial mobilizations of the 20th century. These are not merely data centres; they are modern cathedrals of compute, consuming energy on the scale of nation-states to power the next generation of synthetic cognition. However, a shadow looms over this expansive growth. A “circular economy” of funding has emerged, where chip makers invest in the very cloud providers that purchase their hardware, fuelling fears of a catastrophic asset bubble reminiscent of the dot-com crash. As valuations detach from current revenue realities, the market asks a critical question: is this the buildup to a new industrial revolution, or a prelude to a correction or even a crash?
Please read on Part I – The Model Landscape: The Frontier of Reasoning
The continuous process of operationalizing machine learning models to get business value requires observability, monitoring, feedback mechanism to retrain the models whenever necessary.
Gartner predicted in 2020 that, 80 percent of AI projects would remain alchemy i.e. run by wizards whose talents will not scale in the organization and that only 20 percent of analytical insights will deliver business outcomes by 2022. Rackspace corroborates that claim in a survey completed in January of 2021 saying that 80 percent of companies are still exploring or struggling to deploy ML models.
The general challenges are that most of the models are difficult to use, hard to understand, have least explainability and are computationally intensive. With these challenges, it is very hard to extract the business value. The goal of MLOps is to extract business value from the data by efficiently operationalizing ML models at scale. A data scientist may find a model which functions as per business requirements, but deploying the model into production with observability, monitoring and feedback loop complete with automated pipelines, at low expense, high reliability and at scale require entirely different set of skills. This can be achieved in parallel collaboration with DevOps teams.
An ML engineer builds ML pipelines that can reproduce the results of the models discovered by the data scientist automatically, inexpensively, reliably and at scale.
MLOps Principles
Here are a few principles to keep them in check for better MLOps:
a) Tracking or Software Configuration
ML models are software artifacts that need to be deployed. Tracking provenance is critical for deploying any good software and typically handled through version control systems. But, building ML models depends on complex details such as data, model architectures, hyper parameters and external software. Keeping track of these details is vital, but can be simplified greatly with the right tools, patterns, and practices. For example, this complexity could be simplified by adopting dockerization and/or kubernetization of all components and overlaying usual DevOps version controls.
b) Automation and DevOps
Automation is key to modern DevOps, but it’s more difficult for ML models. In a traditional software application, a continuous integration and continuous delivery (CI/CD) pipeline would pick up some versioned source code for deployment. For an ML application, the pipeline should not only automate training models, but also automate model retraining along with archival of training data and other artifacts.
c) Monitoring/Observability
Monitoring software requires good logging and alerting, but there are special considerations to be made for ML applications. All predictions generated by ML models should be logged in such a way that enables traceability back to the model training job. ML applications should also be monitored for invalid predictions or data drift, which may require models to be retrained.
d) Reliability
ML models can be harder to test and computationally more expensive than traditional software. It is important to make sure your ML applications function as expected and are resilient to failures. Getting reliability right for ML requires some special considerations around security and testing.
e) Cost Optimization
MLOps are more deeply involved with cost intensive infrastructure resources and personnel. Continuous cost monitoring and making necessary adjustments from time to time to optimize the cost as well as to drive more business value is extremely important. For some of the models, training could be the cost intensive part of the work, when compared to entire life cycle of the model and its operations. But this cost equation could change entirely when model gets deployed and scaled to numerous instances. For example, initially Alexa’s speech to text, NLP, NLG related model training was cost intensive in terms of collecting, processing the data and training the models using expensive computational resources. After the models are deployed on the cloud and scaled to planet level, most of the cost shifted to inference layer part of the MLOps.
These kinds of cost dynamics can be tackled by estimating and monitoring the costs, adopting right technologies, architectures and processes.
In the above example, inference layer cost is off-loaded to the device itself partially, instead of utilizing the cloud resources in every instance.
Even the training cost will have different equation when federated learning kind of architectures are adopted. Apart from these dynamics, standardizing on the right tools for tracking (and training) models will noticeably reduce the time and effort necessary to transfer models between the data science and data engineering teams.
Model Registry
A model registry acts as a location for data scientists to store models as they are trained, simplifying the bookkeeping process during research and development. Models retrained as part of the production deployment should also be stored in the same registry to enable comparison to the original versions.
A good model registry should allow tracking of models by name/project and assigning a version number. When a model is registered, it should also include metadata from the training job. At the very least, the metadata should include:
Location of the model artifact(s) for deployment.
Revision numbers for custom code used to train the model, such as the git version hash for the relevant project repository.
Information on how to reproduce the training environment, such as a Dockerfile, Conda environment YAML file, or PIP requirements file.
References to the training data, such as a file path, database table name, or query used to select the data.
Without the original training data, it will be impossible to reproduce the model itself or explore variations down the road. Try to reference a static version of the data, such as a snapshot or immutable file. In the case of very large datasets, it can be impractical to make a copy of the data. Advanced storage technologies (e.g. Amazon S3 versioning or a metadata system like Apache Atlas) are helpful for tracking large volumes of data.
Having a model registry puts structure around the handoff between data scientists and engineering teams. When a model in production produces erroneous output, registries make it easy to determine which model is causing the issue and roll back to a previous version of the model if necessary. Without a model registry, you might run the risk of deleting or losing track of the previous model, making rollback tedious or impossible. Model registries also enable auditing of model predictions.
Some data scientists may resist incorporating model registries into their workflows, citing the inconvenience of having to register models during their training jobs. Bypassing the model-registration step should be discouraged as a discipline and disallowed by policy. It is easy to justify a registry requirement on the grounds of streamlined handoff and auditing, and data scientists usually come to find that registering models can simplify their bookkeeping as they experiment.
Good model-registry tools make tracking of models virtually effortless for data scientists and engineering teams; in many cases, it can be automated in the background or handled with a single API call from model training code.
Model registries come in many shapes and sizes to fit different organizations based on their unique needs. Common options fall into a few categories:
Cloud-provider registries such as Sagemaker Model Registry or Azure Model Registry. These tools are great for organizations that are committed to a single cloud provider.
Open-source registries like MLflow, which enable customization across many environments and technology stacks. Some of these tools might also integrate with external registries; for instance, MLflow can integrate with Sagemaker Model Registry.
Registries incorporated into high-end data-science platforms such as Dataiku DSS or DataRobot. These tools work great if your data scientists want to use them and your organization is willing to pay extra for simple and streamlined ML pipelines.
Feature Stores
Feature stores can make it easier to track what data is being used for ML predictions, but also help data scientists and ML engineers reuse features for multiple models. A feature store provides a repository for data scientists to keep track of features they have extracted or developed for models. In other words, if a data scientist retrieves data for a model (or engineers a new feature based on some existing features), they can commit that to the feature store. Once a feature is in the feature store, it can be reused to train new models – not just by the data scientist who created it, but by anyone within your organization who trains models.
The intent of a feature store is not only to allow data scientists iterate quickly by reusing past work, but also to accelerate the work for productionizing models. If features are committed to a feature store, your engineering teams can more easily incorporate the associated logic into the production pipeline. When it’s time to deploy a new model that uses the same feature, there won’t be any additional work to code up new calculations.
Feature stores work the best for organizations that have commonly used data entities that are applicable to many different models or applications. Take, for example, a retailer with many e-commerce customers – most of that company’s ML models will be used to predict customer behavior and trends. In that case, it makes a lot of sense to build a feature store around the customer entity. Every time a data scientist creates a new feature to better represent customers, it can be committed to the feature store for any ML model making predictions about customers.
Another good reason to use feature stores is for batch-scoring scenarios. If you are scoring multiple models on large batches of data (rather than one-off/real-time) then it makes sense to pre-compute the features. The pre-computed features can be stored for reuse rather than being recalculated for every model.
MLOps Pipeline
More efficient pipelines are constructed in combination with DevOps. Here are outlined steps:
Establish Version Control
Implement CI/CD pipeline
Implement proper logging, centralized log stash, retrieval and querying the logs.
Monitor
Iterate for continuous improvement
Conclusion
Developing an ML production pipeline that delivers business value is extremely challenging and can be mitigated with right deployment of resources, tools, personnel, expertise, and best practices. Remember to keep it simple, iterate it to continuously improve till it meets necessary business value.
When everything goes algorithmic nowadays, why not Portfolio Management?
“Algorithmic Portfolio Management” gets a few thousand results on Google, compared to about 9 million results for “Algorithmic Trading” and in LinkedIn training, one gets zero results as on date!
In algorithmic trading or algo trading for short, preprogrammed algorithms or set of processes execute the trades. Its volumes have steadily increased over years, reaching about 60-80% of the total trading volumes depending on the markets, higher in advanced equity and forex markets and with about 40-50% of trading volume being generated in commodity markets. It also increases volatility and certain risks with millions to billions of market value getting wiped off within minutes and then recovering.
The top reasons for using algo trading are – ease of use, improved trader productivity, consistency of execution performance, lower costs/commissions, better monitoring and high speed/lower latency. Money management fund managers use algo trading to implement their investment decisions. There are traditional strategies such as mean reversion, price or earnings momentum, value and multi-factor or combination of multiple strategies and machine learning based ones such as artificial neural networks, k-NN and Bayes etc.
One specific trend over the years has been diminishing alpha and it is increasingly becoming difficult for actively managed funds to beat their benchmark indices, after expenses. ETFs are making a comeback or gaining mind and market share in the recent years. In the US, passive ETFs have attracted more investments than passive mutual funds. In order to keep the growing tendency of operational and management costs going up, there is an increasing need to leverage technology to be more efficient and effective.
Then there are quant funds, in which securities to invest are chosen through quantitative analysis based on numerical data and without any subjective intervention. While their cost of management is lower as fund managers’ efforts and interventions are much lower, their performance has not been consistent over long time.
So, how is Algorithmic Portfolio Management different from algo trading and is there a case for it to be similarly popular going forward, in this algorithm driven world? It is likely to be so, and let us look at it, along with the causes and trends that would drive it up in future.
Robo-advisory services, which provide algorithmic financial planning services to individuals after collecting their information, have been getting popular. They started with passive indexing strategies and moved onto more sophisticated optimization with variants of modern portfolio theory, tax loss harvesting and retirement planning.
With the advent of ever-increasing computational power and availability of broader and deeper data, Machine Learning brings in more sophistication to the algorithms. Machine Learning (ML) and Artificial Intelligence (AI) make analysis of new forms of data such as unstructured ones, hitherto not practical. While absence of investors’ human biases and subjective judgements are touted as advantages, AI/ML models can have their own biases depending on the data fed to them, deficiencies and limitations of the algorithms used and may even reflect the biases and preferences of algorithm constructors.
In Algorithmic Portfolio Management, a portfolio of assets and sub-assets need to be managed for better risk adjusted returns. That is a key difference when compared to algo trading, which is more of one dimensional, focused on single security at a time. So, the key aspects of Algorithmic Portfolio Management are:
Asset Allocation
Portfolio Construction
Portfolio Execution
Performance Monitoring and Evaluation
Rebalancing
Asset allocation is the single biggest factor that determines a large percentage of the returns or variance in the returns of the portfolio over long periods. Efficiency Frontier can optimize the portfolio for low risk and high expected return or vice versa. Diversification with negatively or low correlated securities lower the standard deviation or the risk. Monte Carlo simulation is used for risk analysis by producing distributions of possible outcomes. Apart from these age old and traditional techniques, principal component analysis can be used for feature selection i.e. to choose the parameters and aspects that matter and ML algorithms can be used for better optimization. While there are diminishing benefits with greater diversification, machine driven algorithmic approach can make management of higher number of securities more effective and easier than with human based processes.
Portfolio construction involves careful selection of securities for better risk adjusted returns. Algorithmic frameworks including macro and micro level decisions can be used for greater alignment of investment objectives and risk profiles.
Portfolio execution in terms of buying and selling securities can leverage algo trading for lower market impact and better outcomes. Higher percentage of larger ticket size trades of institutions tend to use algo trading more than for smaller trades.
With the availability real time and near real time data and computational power, portfolio performance monitoring and evaluation can be more frequent and thus triggering effective rebalancing in near real time based on market data for more optimal returns.
Passive rebalancing including calendar and/or percentage-based rebalancing is used for robo-advisory approaches. Algorithmic management can bring in more sophisticated and optimization for active and dynamic asset allocation and rebalancing driven by them. Dynamic asset allocation is not driven by fixed percentage allocations, but involves a more nuanced approach of changing the securities and their constitution based on analysis or algorithmic output.
In conclusion, fund managers are expected to leverage algorithmic portfolio management to complement subjective decisions, to reduce the costs of management and for greater alpha, though portfolios may not be driven entirely by algorithms in near future.
This interview with the cofounder Bhanu, IET Smart Cities Chapter Chair talks about 5G, its advantages, how it is different from earlier generations and its impact on jobs, economy and cities.